Collection framwork
Collection framwork에 대해 공부한 내용을 바탕으로 작성한 글이기 때문에 잘 못 된 내용이 있을 수 있습니다.
댓글로 알려주시면 수정하도록 하겠습니다!
Collection framwork
컬렉션 프레임워크란 Java에서 다수의 데이터를 효과적으로 처리할 수 있는 표준화된 방법을 제공하는 클래스의 집합입니다. 즉, 데이터를 저장하는 자료 구조와 데이터를 처리하는 알고리즘을 구조화하여 클래스로 구현해 놓은 것이라 볼 수 있습니다. 자주 쓰이는 컬렉션 프레임워크의 클래스 구조도를 보면 아래의 이미지와 같습니다. (아래의 이미지에 나와있는 구조도는 간략화되어 있으며, 실제로는 훨씬 더 많고 복잡합니다.)
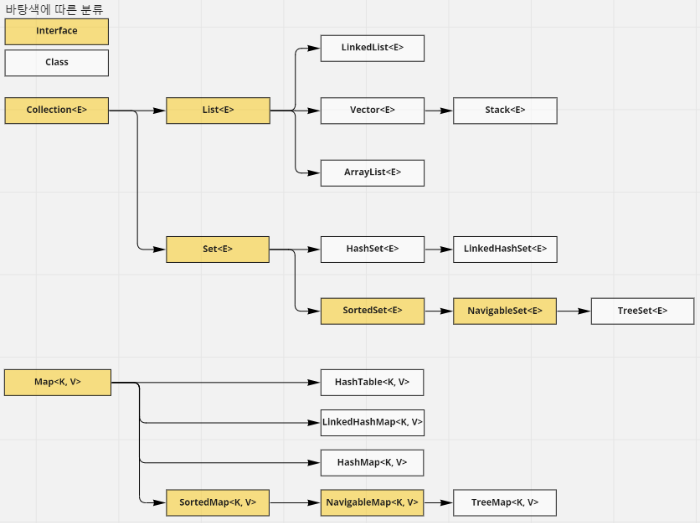
이미지에서 볼 수 있듯이 컬렉션 프레임워크는 크게 List, Set, Map 3가지로 나눌 수 있습니다.
여기서 List와 Set은 객체를 추가, 삭제, 검색하는 방법에서 공통점이 많이 존재하며, 이 인터페이스들의 공통된 메서드들을 모아 Collection 인터페이스에 정의해 두었습니다.
Map의 경우 Key와 Value를 하나의 쌍으로 묶어서 관리하는 구조로 List와 Set과는 사용법이 달라 독립된 인터페이스로 분리되어 있습니다.
각 인터페이스별 특징과 구현 클래스는 다음과 같습니다.
| 인터페이스 | 특징 | 구현 클래스 |
| List | 순서 유지, 중복 저장 가능 | ArrayList, Vector, Stack, ... 등 |
| Set | 순서 유지 X, 중복 저장 불가능 | HashSet, TreeSet, ... 등 |
| Map | 키와 값의 쌍으로 저장, 순서 유지 X, 키는 중복 저장 불가 |
HashMap, HashTable, ... 등 |
List<E>
객체를 일렬로 늘어놓은 구조, 요소의 중복을 허용하고 저장 순서를 유지
객체를 인덱스로 관리하기 때문에 객체 저장 시 자동으로 인덱스를 할당하여 저장
할당된 인덱스로 객체를 검색, 삭제할 수 있는 기능을 제공
아래의 인용구는 oracle에서 제공하는 Java document에서 interface List<E> 항목 시작에 적혀있는 설명입니다.
An ordered collection (also known as a sequence). The user of this interface has precise control over where in the list each element is inserted. The user can access elements by their integer index (position in the list), and search for elements in the list.
출처 : https://docs.oracle.com/javase/7/docs/api/java/util/List.html
ArrayList
컬렉션 프레임워크에서 가장 빈번하게 사용되는 클래스 중 하나
배열의 특성을 그대로 사용하는 클래스, 차이점은 값을 저장할 수 있는 크기가 가변적이라는 점
배열의 특성을 그대로 사용하기 때문에 저장되는 데이터가 메모리상에서 연속적으로 저장되어 관리됨
기능적인 측면에서는 Vector 클래스와 동일하지만 Vector 클래스를 개선한 클래스가 ArrayList 클래스
동기화 측면에서는 Vector 클래스는 동기화를 보장하지만 ArrayList 클래스는 동기화를 보장하지 않는 클래스라는 차이점 존재
중간에 객체를 삽입하거나 저장된 객체를 제거하는 경우, 해당 인덱스의 다음부터 마지막까지 저장되어 있던 객체가 모두 이동하게 되므로 번번한 객체 삽입 및 삭제가 일어나는 구조엔 부적합 (마지막 인덱스에서의 삽입 및 삭제는 상관 없습니다.)
하지만 데이터가 연속으로 저장되어 관리되기 때문에 검색 성능은 좋기 때문에 삽입 및 삭제가 항상 마지막 인덱스에서 이루어 지거나 데이터가 고정된 구조라면 ArrayList 클래스 사용이 적합
사용방법을 간단한 예제 코드로 알아보도록 하겠습니다.
import java.util.ArrayList;
import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<String>(); // List<String> 참조 변수에 ArrayList<String> 인스턴스 대입
list.add("C"); // list의 맨 마지막에 해당 객체 삽입
list.add("C++");
list.add("Java");
list.add("Golang");
list.add(2, "Rust"); // list의 2번 인덱스에 해당 객체 삽입
int size = list.size(); // 현재 저장된 총 객체 수 얻기
String first = list.get(0); // 0번 인덱스에 저장된 객체 얻기
System.out.println("현재 list의 크기 : " + size);
System.out.println("현재 list의 0번째 인덱스 객체 값 : " + first);
for(int i = 0; i < size; i++) {
String str = list.get(i);
System.out.println("list[" + i + "] : " + str);
}
System.out.println("현재 list의 2번째 인덱스 객체 값 : " + list.get(2));
list.remove(2); // 현재 list의 2번 인덱스에 저장된 객체 제거, 즉 여기선 "Rust" 삭제
System.out.println("현재 list의 2번째 인덱스 객체 값 : " + list.get(2));
}
}
출력 -----
현재 list의 크기 : 5
현재 list의 0번째 인덱스 객체 값 : C
list[0] : C
list[1] : C++
list[2] : Rust
list[3] : Java
list[4] : Golang
현재 list의 2번째 인덱스 객체 값 : Rust
현재 list의 2번째 인덱스 객체 값 : Java혹시나 ArrayList 클래스의 크기가 가변적일 수 있는지 궁금하다면 아래의 내용을 참고해주세요.
ArrayList 클래스를 사용하여 데이터를 저장하게 될 때, 정해진 크기를 넘겨서 저장하려고 한다면 자동으로 크기를 늘려서 저장하게 된다.
이 동작의 내부로 들어가 보면 Arrays.copyOf() 메서드를 사용하여 크기가 더 큰 배열에 현재 값들을 복사하여 늘리게 됩니다.
즉, ArrayList를 작은 크기로 생성 후 많은 데이터를 넣게 되면 크기를 늘리기 위하여 계속하여 배열의 복사가 일어나게 되므로 오버헤드가 발생하게 되어 성능이 하락하게 됩니다.
따라서 처음 생성 시 사용할 크기에 여분을 두어 사용하는 것이 가장 좋다고 볼 수 있습니다.
추가로, 배열의 크기를 늘리는 과정에서 "이전 배열의 크기 / 2"의 크기만큼 증가시킵니다. (즉, 이전 크기의 1.5배로 확장)
해당 내용을 참고한 블로그 : 링크
LinkedList
저장되는 데이터가 ArrayList나 배열처럼 연속적으로 존재하는 것이 아니라, 불연속적으로 존재하며 데이터 간 서로 연결되어 구성
ArrayList와 장단점이 반대라고 생각하면 편한 클래스
즉, LinkedList 클래스는 데이터 검색은 느리지만 추가, 삭제 과정이 빠르기 때문에 빈번한 데이터 추가, 삭제에 적합한 구조
사용방법은 위 ArrayList 예제 코드에서 아래와 같이 코드를 변경하면 끝이다.
import java.util.ArrayList;
List<String> list = new ArrayList<String>();
위 코드를 아래와 같이 변경
import java.util.LinkedList;
List<String> list = new LinkedList<String>();
Iterator
갑자기 구조도에 보이지도 않던 Iterator라는 게 왜 튀어나왔는지 의문이 들 수 있습니다.
Iterator는 Collection framwork에서 저장된 요소를 읽어오는 방법으로 사용되는 인터페이스이기 때문에 추가로 정리를 하였습니다.
Iterator 인터페이스의 구현체를 반환하는 iterator() 메서드는 Colleciton 인터페이스에 선언되어 있으므로, Collection 인터페이스를 상속받는 List와 Set 인터페이스의 구현 클래스에 구현되어 있습니다.
C 또는 C++을 공부했던 사람이라면 Iterator를 포인터 변수를 활용한 데이터 참조라고 생각하시면 이해하기 편하실 수 있습니다.
Iterator 인터페이스에 선언된 메서드 (아래의 표에 누락된 메서드 존재)
| 리턴 타입 | 메서드 | 설명 |
| boolean | hasNext() | 요소가 더 존재하는 경우 true, 그렇지 않은 경우 false 반환 |
| E | next() | iteration의 다음 요소를 반환 다음 요소가 없다면 "NoSuchElementException" 에러 발생 |
| void | remove() | 마지막으로 반환된 요소 제거 즉, 현재 지정되어 있는 요소를 제거 상황에 따른 에러 발생 가능 |
next() 메서드를 통해 하나의 요소를 갖고 와서 사용하게 되며, 다음 요소가 없다면 에러를 발생하기 때문에 hasNext() 메서드를 통해 다음 요소가 있는지 확인을 한 후 next() 메서드를 사용하는 것이 좋습니다.
remove() 메서드의 경우 next() 메서드 실행 전이거나 next() 메서드 실행 후 remove() 메서드를 2회 이상 호출하게 되면 "IllegalStateException" 에러가 발생하게 되며, 해당 iterator가 remove() 메서드를 지원하지 않는 경우에 호출 시 "UnsupportedOperationException" 에러가 발생하게 됩니다.
사용방법을 예제 코드를 통해 알아보도록 하겠습니다.
import java.util.ArrayList;
import java.util.List;
import java.util.Iterator;
public class Test {
public static void main(String[] args) {
List<String> list = new LinkedList<String>(); // List<String> 참조 변수에 ArrayList<String> 인스턴스 대입
list.add("C"); // list의 맨 마지막에 해당 객체 삽입
list.add("C++");
list.add("Java");
list.add("Golang");
list.add(2, "Rust"); // list의 2번 인덱스에 해당 객체 삽입
Iterator<String> it = list.iterator();
System.out.println(it.next()); // list의 첫 번째 요소인 "C" 반환되어 및 출력
it.remove(); // 마지막으로 반환된 요소인 "C" 제거
System.out.println(it.next()); // list의 두 번째 요소인 "C++" 반환되어 및 출력
it.remove(); // 마지막으로 반환된 요소인 "C++" 제거
// it.remove(); // 연속으로 remove() 메서드를 호출하였기에 "IllegalStateException" 에러 발생
System.out.println(it.next()); // list의 세 번째 요소인 "Rust" 반환되어 및 출력
System.out.println(it.next()); // list의 네 번째 요소인 "Java" 반환되어 및 출력
System.out.println(it.next()); // list의 다섯 번째 요소인 "Golang" 반환되어 및 출력
// System.out.println(it.next()); // 다음 요소가 없는데 next() 메서드를 호출하였기에 "NoSuchElementException" 에러 발생
if(it.hasNext()) // 다음 요소가 없으므로 false 반환
System.out.println(it.next()); // 조건문이 false이기 때문에 실행 X
// 이후 list의 값을 확인해보면 "C"와 "C++"이 제거된 {"Rust", "Java", "Golang"}인 것을 알 수 있다.
}
}
출력 -----
C
C++
Rust
Java
Golang
Set
요소의 중복을 허용하지 않고, 입력된 순서를 기억하지 않는 구조. 집합이라고도 부릅니다.
HashSet
Set 인터페이스를 구현한 가장 대표되는 클래스. Set 인터페이스의 특징을 그대로 구현한 클래스.
즉, 입력된 순서를 유지하지 않는 특징으로 인해 당연하게도 데이터 정렬이 불가합니다.
내부적으로 HashMap을 이용하여 입력받은 데이터를 hashing 하여 저장, 관리되기에 HashMap이라 이름이 붙혀졌습니다.
사용방법을 예제 코드를 통해 알아보도록 하겠습니다.
import java.util.HashSet;
import java.util.Set;
import java.util.Iterator;
public class Main {
public static void main(String[] args) {
HashSet<String> set = new HashSet<String>(); // List<String> 참조 변수에 ArrayList<String> 인스턴스 대입
set.add("C"); // list의 맨 마지막에 해당 객체 삽입
set.add("C++");
set.add("Java");
set.add("Golang");
// set.add(2, "Rust"); // Set 인터페이스는 순서가 없으므로 index도 존재하지 않는다.
set.add("Java"); // 중복된 값 입력
for(String e : set) // 향상된 for문(for each문) 사용한 출력
System.out.println(e);
/* // Set에서의 Iterator 사용 예제
Iterator<String> it = set.iterator(); // iterator를 사용한 출력
while(it.hasNext()) // 다음 요소가 존재하는 경우에만
System.out.println(it.next());
*/
}
}
출력 -----
Golang
Java
C++
C위 코드를 보면 "Java"를 중복하여 2회 입력을 시켰으나 출력은 1회만 되는 것을 확인할 수 있습니다. 이로 인해 중복 저장을 허용하지 않는 특징을 알 수 있습니다.
또한 위 출력 예시와 다르게 출력이 될 수 있는데, 이는 입력된 순서를 기억하지 않는 특징으로 인한 결과입니다.
정리 (cheat sheet)

마치며
머리글에도 작성을 했었지만 틀린 내용이 있을 수 있으며, 그러한 내용들을 댓글로 남겨주시면 반영하도록 하겠습니다!
해당 글을 읽어주신 모든 분들에게 도움이 되는 내용이었으면 좋겠습니다.
추가로 Collection framwork의 구현 클래스들의 메서드 시간 복잡도가 궁금하신 분들이 계시다면 아래의 블로그 참고를 추천드립니다. 해당 글을 작성하면서 궁금해서 찾아보다가 정리를 잘 해두신 분이 계셔서 공유드립니다.
시간 복잡도 정리 블로그 : 링크